AI is rapidly transforming how we build, interact with, and deliver software. However, many developers feel overwhelmed by the vast array of tools, terms, and capabilities in the GenAI ecosystem. If you’ve ever asked:
- “What’s the difference between fine-tuning and RAG”
- “Do I need 24B parameters to run a chatbot?”
- “What is RAG, and why is everyone talking about it?”
This blog is for you.
In this blog, we’ll explore Levels of AI adoption, progressing from basic usage of ChatGPT to running your own fine-tuned models or even a glimpse of pretraining one from scratch. We’ll also demystify key GenAI jargon so you can speak the language of AI confidently.
The AI Jargon Jungle: Demystifying GenAI Terms
Feel free to skip this section if you’re already familiar with AI jargon.

| Term | Definition |
|---|
| Inference | Using a trained model to answer a question.
Like typing into Google: You ask it replies. ,
That reply step is inference. |
| Pretraining | Teaching the model before it can answer questions.
Like reading millions of books to “learn how language works” so later, it can reply when you ask. |
| Fine-tuning | Imagine you hire a general translator who knows many languages. But you give them extra training only on medical terms.
Now, they’re much better at translating medical documents.
That extra training = fine-tuning. |
| Parameters | The model’s “settings” it learned during training.
Like knobs on a sound mixer billions of tiny adjustments that help it decide what word comes next. |
| 7B vs 24B | How many parameters (knobs) the model has.
7B = 7 billion knobs.
24B = 24 billion knobs.
More knobs can capture more patterns often smarter, but needs more compute. |
| Quantization | Shrinking the model to use less memory.
Like storing images in JPG instead of RAW smaller size, still works well. |
| Perplexity | How “surprised” the model is while predicting words.
Lower perplexity model is confident and fluent.
Higher perplexity model is confused or uncertain. |
| Embeddings | Turning words into numbers that capture meaning.
Like mapping words into a coordinate system, where “king” and “queen” are close, but “banana” is far away. |
| Tokenization | Breaking text into smaller pieces the model can understand.
Like splitting “ChatGPT is awesome” into [ “Chat”, “G”, “PT”, " is", " awesome" ]. |
| Context Window | How much text the model can see at once
Like how many previous chat messages it can read to answer you. Bigger window remembers more which results in better answers. |
| Distillation | Teaching a small model to copy a big model’s knowledge
Like a senior engineer mentoring a junior the junior learns just enough to do most tasks, faster and cheaper. |
| RAG | Letting the model look up external information before answering.
Like a student checking notes or Google while writing an answer more accurate, less guessing. |
| LoRA / QLoRA | A shortcut way to fine-tune big models cheaply.
Like adding a small plugin to a huge app, you don’t rebuild the full app, just attach the piece you need for new tasks. |
| Agentic AI | Models that can plan and take actions, not just reply. “Book flight , find hotel, create itinerary” it handles the full workflow. |
| MCP | A standard way to give AI models structured information before answering. |
How LLMs Work ?
At its core,
LLMs (Large Language Models) are transformer-based machine learning models that predict the next word in a sentence.
Think of them as extremely advanced autocomplete engines.
Any serious discussion about LLMs will eventually point you to the famous paper: Attention Is All You Need. That being said, it’s not exactly beginner friendly, I can say this from experience it took me more than one read to grasp it fully.
Before diving into how LLMs work, let’s first briefly touch on what they are and why they exist a bit of history helps.
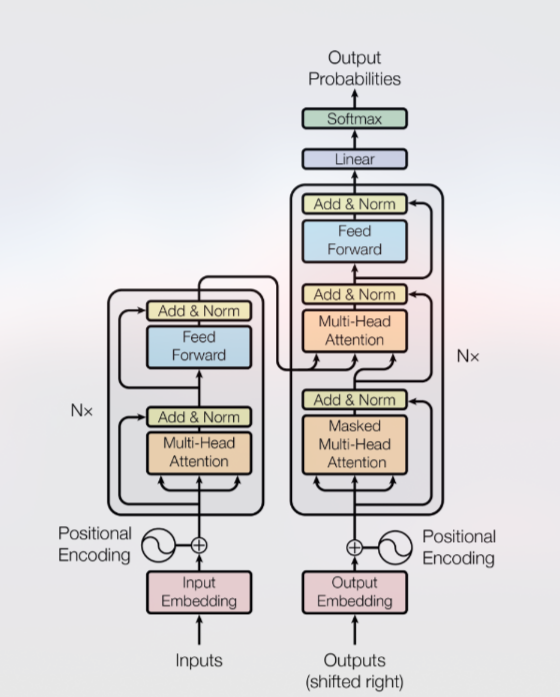
Before 2017, NLP relied on older models like RNNs, LSTMs, and GRUs, which struggled with long-range dependencies in text. The breakthrough came with transformers.
Early models like BERT, GPT were originally developed to tackle classic NLP problems like translation, sentiment analysis, question answering, etc.
In that sense, LLMs are direct successors of earlier NLP systems but with much broader generalization and capability thanks to transformers.
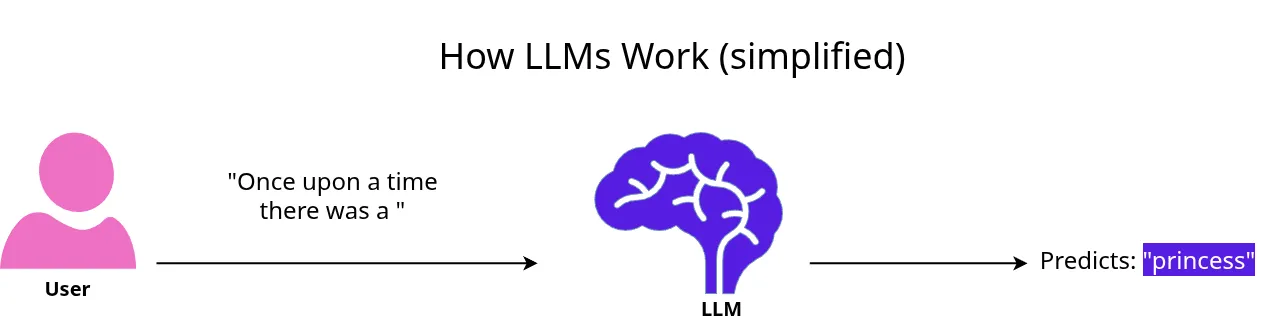
That’s how it works, It keeps predicting the next word using everything it has seen so far. That’s it, Everything else like answering questions, writing code, summarizing text is just a smart version of autocomplete.
How Did It Get So Smart?
Before it can predict well, an LLM has to learn language like a person reading millions of books, articles, websites, and conversations.
This learning process is called pre-training.
The model reads text and constantly tries to guess the next word.
If it gets it wrong, it updates itself to do better next time.
This happens billions of times until it gets really good at understanding how words fit together.
Inside an LLM is a special type of neural network called a transformer.
The key ingredient of a transformer is something called attention it helps the model focus on the most important words when making a prediction.
The 7 Levels of AI Adoption
Each level introduces higher control, complexity, and customization.
Level 0: AI User
An AI user, is someone who interacts with a large language model by simply typing instructions, known as prompts, and reading the model’s responses. They don’t build the model, fine-tune it, or deploy it they just use it. If you’ve ever typed something into ChatGPT, Claude, Gemini, or any AI chatbot and hit “Enter” to see what comes back, congrats you’re a AI user. These users rely on their ability to ask the right questions and structure their requests clearly. They may not need deep technical knowledge, but great prompt users understand how to guide the model, test its limits, and rephrase their queries to get better results. It’s like talking to a very smart assistant the better your questions, the better the answers. Whether you’re writing emails, brainstorming ideas, or summarizing articles, you’re still using a language model and that’s exactly what makes you a consumer in the LLM world.
- Tools: ChatGPT, Claude, Gemini
- Skills: Prompt writing basics
- Limitations: No customization, no control over outputs
Level 1: Prompt Engineering
A Prompt Engineer is someone who knows how to talk to LLMs in a structured, strategic way to get the most accurate, useful, and reliable output possible.
A prompt engineer is someone who specializes in crafting the right instructions known as prompts to get the most accurate, useful, or creative output from a language model like ChatGPT, Claude, or Gemini. While it may seem like they’re just typing smart questions, prompt engineering is more like programming in plain English. These experts shape how the model responds, control tone and output structure, and help guide the model’s reasoning to complete complex tasks all without touching the model’s code or architecture.
For example, instead of asking the model:
> “Tell me about Paris.”
A prompt engineer might say:
> “You are a friendly travel guide. Write a 3-paragraph summary of Paris for someone visiting for the first time. Include key landmarks, a bit of history, and one fun local tip.”
This version gives the model context, tone, length, and structure and usually leads to a much better, more targeted result.
Prompt engineers blend strong communication skills with a deep understanding of how language models behave. They know the model doesn’t truly understand language it predicts the next most likely word based on training data. So crafting good prompts means giving the model the right signals, cues, and patterns to follow. A big part of the job is knowing how to think like the model and preempt mistakes before they happen.
A common technique in prompt engineering is called Chain-of-Thought prompting, where you ask the model to think step by step instead of jumping to an answer. For example:
Bad Prompt - “What is 38 × 47?”
Good Prompt - “Let’s solve 38 multiplied by 47 step by step.”
That small change often improves the model’s reasoning, especially in math, logic, or coding tasks.
Another powerful technique is role prompting asking the model to take on a specific persona or job. This helps align the tone, context, and structure of the response with your goal.
For example:
“Act as a senior backend engineer. Explain how to optimize a REST API for high concurrency.”
Now you’re likely to get a more focused, technically sound answer instead of a generic one. Checkout - https://www.promptingguide.ai/prompts , For more prompt engiering techniques.
And perhaps most importantly, prompt engineering is iterative. It’s rarely perfect on the first try. Prompt engineers test and tweak prompts, experiment with different phrasings, add examples (called few-shot prompting), or even build mini workflows that chain prompts together. In production, they often integrate with tools like LangChain, OpenAI’s function calling, or vector search (RAG) to make LLMs part of bigger systems.
In short, a prompt engineer is someone who doesn’t just use AI they know how to talk to it. They turn vague goals into structured instructions that the model can follow reliably. In the world of generative AI, this is becoming one of the most critical skills part communication, part product thinking, and part AI psychology.
Limitations of Prompt Engineering. And When Not to Use It
Prompt engineering is powerful but not foolproof. It can’t fix a model’s lack of domain knowledge, and it struggles with tasks needing precise logic, long memory, or consistent structured output. Prompts alone are often too fragile for production use where accuracy and reliability matter. If you need deeper control, domain-specific behavior, or long-term memory, techniques like RAG, fine-tuning, or tool integration are better options.
- Skills: JSON output, function calling, chain-of-thought
- Tools: OpenAI Playground, LangChain templates
Level 2: Local or Cloud Deployed Models
At this stage, you’re no longer relying on hosted tools like ChatGPT. Instead, you’re running LLMs yourself either locally on your machine or remotely via cloud APIs or endpoints. This gives you more control, privacy, and sometimes even cost-efficiency, especially for repeated or large-scale use. Tools like Ollama, LM Studio, and Text Generation Inference (TGI) from Hugging Face let you run open models like Mistral, LLaMA, or Gemma with just a few commands. On the cloud side, platforms like Replicate, Hugging Face Inference Endpoints, and AWS SageMaker allow you to deploy and scale your own inference-ready LLM services. However, platform runners need to manage things like VRAM limits, model quantization, inference speed, and security so there’s some devops knowledge involved. You’re essentially treating the LLM like a self-hosted service install it, run it, call it via API, and integrate it into your own apps or workflows.
When running local models with tools like Ollama, you’re suddenly faced with dozens of choices: Mistral, LLaMA, Phi, NeuralChat, OpenHermes, and many more. How do you pick one? First, understand the model name: it often tells you the base architecture (like Mistral), the training style (e.g., Instruct = fine-tuned to follow prompts), and occasionally the version. For example, mistral:7b-instruct-q4 means it’s a 7 billion parameter Mistral model fine-tuned for instructions, with Q4 quantization. Here’s how to decode the key details in a model card:
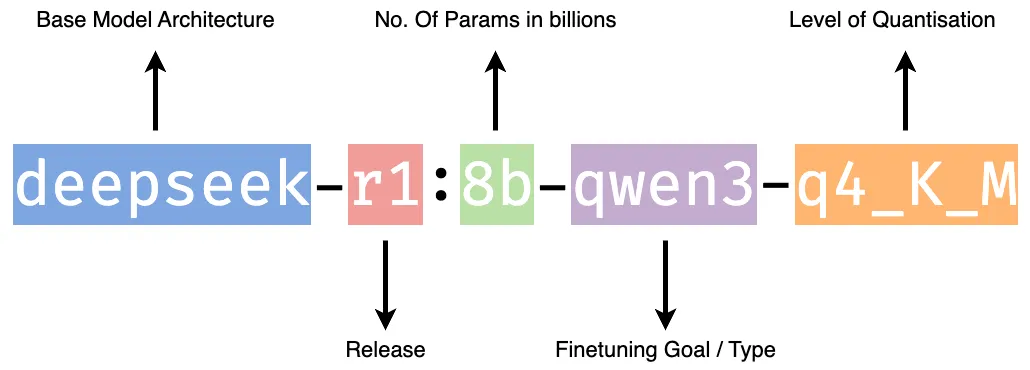
It is an 8 billion parameter DeepSeek model, trained for Qwen-style chat interactions, and quantized to 4-bit for efficient local inference. It’s designed to work well on mid-range GPUs or Apple M-series chips with ~6–8 GB of VRAM.
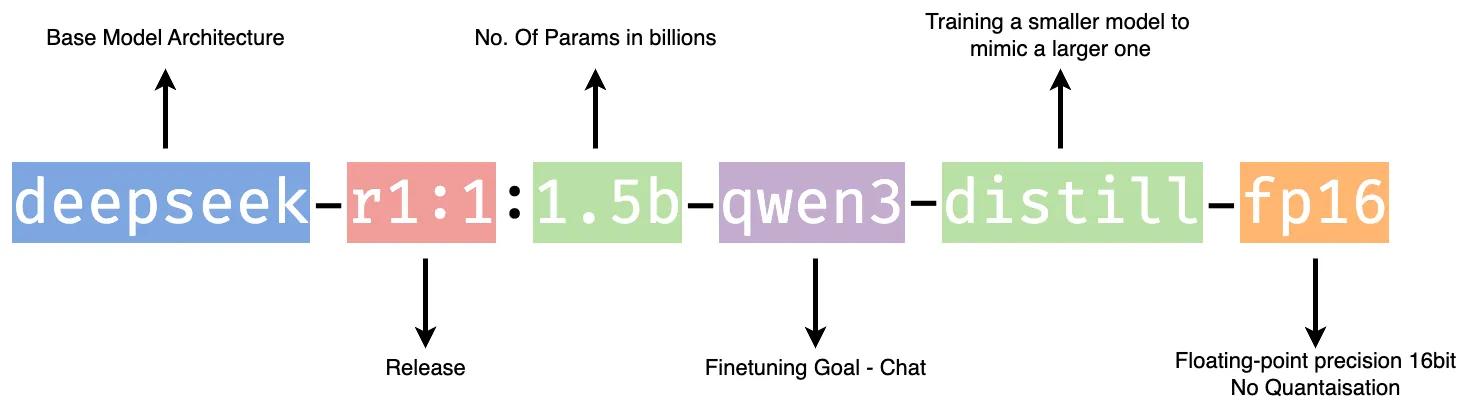
It is a small, chat-friendly, distilled model optimized for high-quality GPU inference. It uses Qwen-style multi-turn formatting, is trained to behave like a helpful assistant, and uses 16-bit floating-point precision (fp16) for a better balance between accuracy and performance at the cost of higher memory usage.
Size (e.g., 7B, 13B): This is the number of parameters more means better reasoning, but slower and heavier on memory.
Quantization (e.g., Q4, Q5_0, Q8_0): Lower Q values run faster with less RAM, but slightly degrade output quality. Q4 is fast, Q8 is more accurate.
Context Length: The number of tokens it can “remember” per prompt. 4k is standard, 16k+ for long documents or chats.
Architecture: Tells you the base model some like Mistral are fast and compact, others like LLaMA are more heavyweight but accurate.
License: Open-source (Apache/MIT) means flexible use, but some models are for research/non-commercial only.
To know how it’ll perform on your system, check the VRAM requirement (typically shown in the model card or docs). A 7B model with Q4 quantization needs around 4–6GB VRAM to run smoothly. If you’re on a MacBook M1/M2 or a mid-range GPU, stick with smaller or more quantized models (q4, q5_0, q6_k).
- Models: Mistral, LLaMA, Gemma, Deepseek
- Tools: Ollama, LM Studio
- Challenges: VRAM, inference speed, quantization
DIY
Running LLMs on your own machine is now incredibly easy with Ollama a CLI tool that lets you download, run, and interact with models like Mistral, LLaMA, DeepSeek, and more using minimal setup. Here’s everything you need to go from zero to first local inference.
Step 1: Install Ollama:
Ollama supports macOS (Intel/Apple Silicon), Linux, and Windows (via WSL2) , choose your installion accourding to the base operating system you are running.
For MacOS:
For Linux:
$ curl -fsSL https://ollama.com/install.sh | sh
Step2: Pull a Model: Use the CLI to pull a model, just like Docker:
$ ollama pull deepseek-r1
Step 3: Run Your First Inference:
You will be presented with input prompt in the temerminal , start typing your first local prompt
> Write a fibonacci program in rust
Additionally Ollama exposes a RESTful API at http://localhost:11434. You can use it to integrate models into your apps
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Explain how neural networks learn."
}'
Level 3: Simple RAG
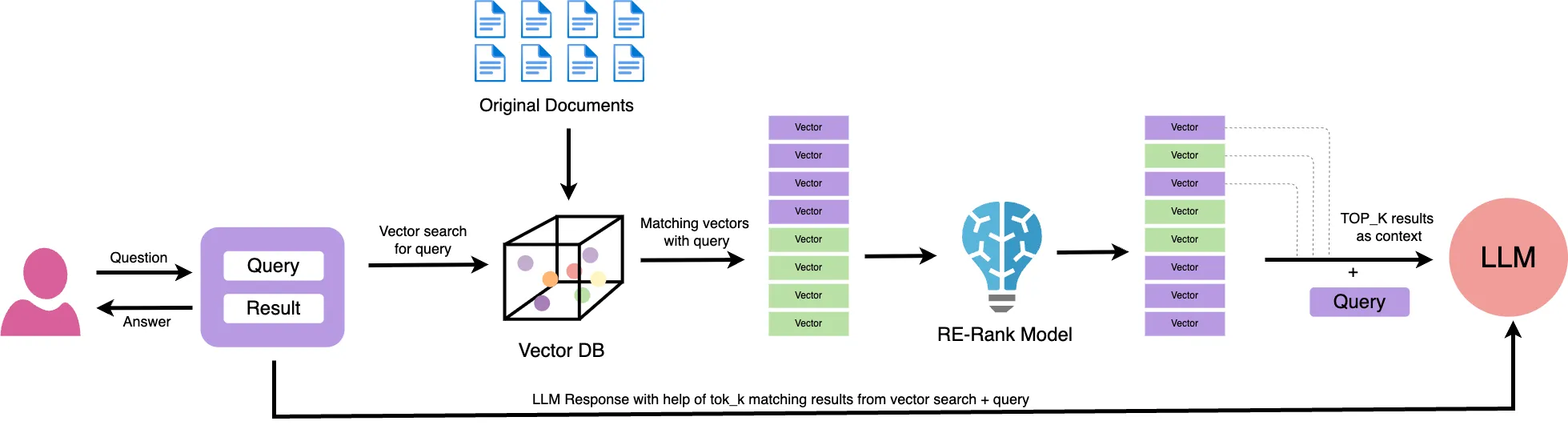
RAG (Retrieval-Augmented Generation) is a method where a language model doesn’t rely only on its pre-trained internal knowledge to answer a question instead, it retrieves relevant external data (documents, PDFs, websites, etc.) at runtime and uses that context to generate accurate, up-to-date, and grounded responses.
Think of it like this: instead of expecting the model to “remember” everything, you give it a quick reference sheet every time you ask something. That sheet (retrieved content) becomes part of the model’s input, allowing it to answer with much more precision and relevance especially for enterprise or domain-specific applications.

Why RAG?
RAG bridges a critical gap: LLMs are powerful but forgetful. They are trained on massive but static datasets and can’t inherently know company policies, new laws, or your private database. That’s where RAG comes in.
With RAG, you can:
Feed the LLM your domain knowledge base, PDFs, FAQs, etc.
Avoid hallucinations by grounding the output in retrieved facts.
Enable domain-specific QA (legal, medical, finance, enterprise internal tools).
Update the knowledge base without re-training the model just update your docs!
Pitfalls of Simple RAG
In short: RAG is not just plug-and-play. It requires careful optimization of chunking, embedding, indexing, and prompt formatting.
While simple RAG (one query → one retrieval → one response) is powerful, it’s not foolproof. Common pitfalls include:
- Garbage in, garbage out: If the retriever pulls irrelevant or noisy documents, the LLM will produce misleading answers.
- Chunking strategy matters: Poorly split documents (too big or too small) degrade retrieval precision.
- No understanding of hierarchy or relationships: Simple RAG can’t reason across multiple documents or understand structured formats.
- No memory: Single-turn RAG doesn’t remember previous questions or context.
- Latency: Each query may require embedding, vector search, and generation slowing down responses.
DIY
Before we start coding, install the libraries that will power the system:
$ pip install langchain langchain-community chromadb sentence-transformers
Here’s what each package does:
- langchain: Core orchestration for LLM pipelines
- langchain-community: Community integrations like Ollama, Chroma, loaders
- chromadb: Vector storage to index and retrieve document embeddings
- sentence-transformers: Provides the embedding model we’ll use to vectorize documents
Also, make sure Ollama is installed and the model you want is pulled. You can install Ollama from https://ollama.com and then pull a model like this:
$ ollama pull deepseek-coder:6.7b-instruct
If you’re on an M1/M2 Mac or a system with 6GB+ RAM, quantized versions like deepseek-r1:1.5b-qwen-distill-q4_K_M will run beautifully.
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
# Load your local documents
loader = TextLoader("data/company_policy.txt")
docs = loader.load()
# Split them into chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
# Create embeddings and vector DB
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectordb = Chroma.from_documents(documents=chunks, embedding=embeddings, persist_directory="./chroma_db")
from langchain_community.llms import Ollama
from langchain.chains import RetrievalQA
# Load local LLM from Ollama (use the exact model name you pulled)
llm = Ollama(model="deepseek-coder:6.7b-instruct")
# Create retriever and RAG chain
retriever = vectordb.as_retriever()
rag_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
# Ask your question!
query = "What is the company's leave policy?"
response = rag_chain.run(query)
print(response)
Summary
- Your question (query) is sent to a retriever.
- The retriever converts your query into a vector and compares it to all document chunks in the vector DB.
- The top-matching chunks (say, top 3) are selected as context.
- This context + your query is passed to DeepSeek running locally via Ollama.
- The model generates a grounded answer using this custom context instead of guessing blindly from pre-trained knowledge.
Level 4: Advanced RAG
Building a basic RAG system where you chunk documents, embed them, store them in a vector DB, and retrieve top-K matches for an LLM is a great first step. But when you’re aiming for production-grade, high-accuracy, or enterprise-scale applications, you’ll quickly run into the limits of “simple RAG.” That’s where Advanced RAG enters the picture.
Advanced RAG goes beyond naive document retrieval + LLM generation. It introduces smart enhancements to make answers more accurate, less redundant, multi-hop capable, and self-correcting. These enhancements include:
| Architecture | Strengths | Use When |
|---|
| Basic RAG | Fast, simple | POC, internal tools |
| RAG + Re-Ranking | High precision | Legal, medical, enterprise |
| Hybrid Search | Balanced coverage | Structured + unstructured data |
| Conversational RAG | Context-aware | Chatbots, assistants |
| Graph-Based RAG | Relational reasoning | Enterprise, complex queries |
| Tool-Augmented RAG | LLM acts with tools | Agents, planning, data + actions |
| Self-Healing RAG | Fault-tolerant | Production, quality-sensitive workflows |
| Refine | Incremental understanding | Factual QA, multi-evidence |
Re-ranking and Validation
Simple RAG retrieves top-K documents based on vector similarity (cosine distance). But sometimes the top match is not the best answer. Advanced RAG uses re-rankers like Cohere Rerank , CrossEncoder models from Hugging Face, or sentence-transformer bi-encoders or free models like Qwen3-Reranker-8B to re-order retrieved chunks based on actual relevance to the query.
Self-Healing
Self-Healing RAG is an advanced Retrieval-Augmented Generation architecture that not only retrieves documents and generates answers but also evaluates the quality of the response and automatically fixes poor results. If an answer is vague, hallucinated, or off-topic, the system “heals” itself by retrying with an expanded query, retrieving more relevant chunks, switching prompts or models, or even escalating to an external tool or human. It uses evaluation strategies like LLM-based feedback, heuristics, or confidence scoring to decide when to retry. This makes RAG more reliable, especially for production use cases where accuracy, trust, and fallback mechanisms are critical.
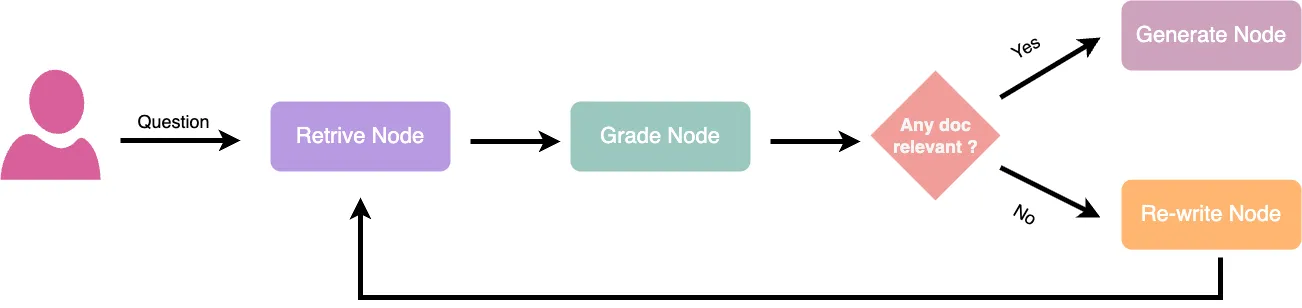
How to Detect a “Bad” Answer?
| Strategy | How it works |
|---|
| LLM-based scoring | Ask another LLM: “Is this a good answer to the question?” |
| Heuristic rules | Check for low word count, repetition, or “I don’t know” phrases |
| Confidence classifiers | Train a binary classifier on past RAG failures |
| Embedding similarity | Compare question → answer vectors for coherence |
| Grounding check | Ask: “Was this answer fully grounded in the retrieved context?” |
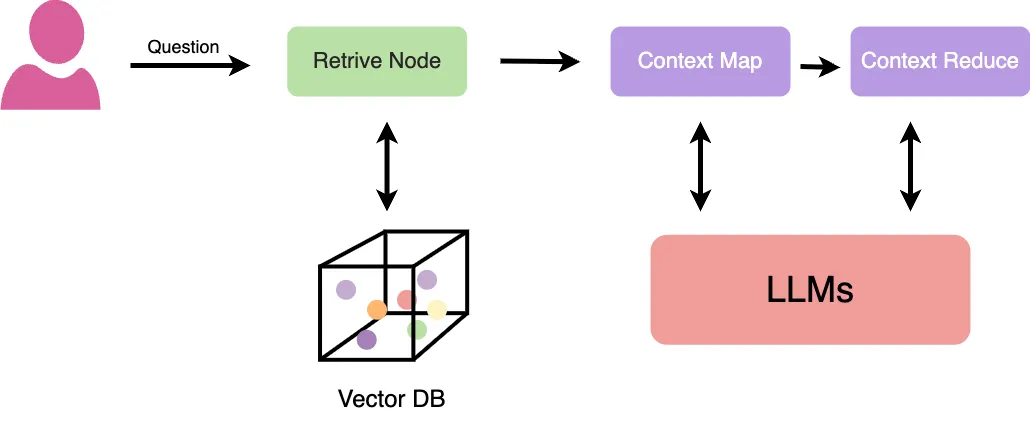
Map-Reduce
Map-Reduce RAG is an advanced RAG architecture designed to handle large document collections or long text inputs that don’t fit into the context window of an LLM. Instead of stuffing all retrieved chunks into a single prompt, the system first maps the query across multiple chunks individually generating partial responses for each. Then, in the reduce phase, it aggregates or summarizes those partial responses into a single coherent answer. This architecture improves factual consistency, allows scalable multi-document summarization, and prevents context overflows. It’s particularly useful when dealing with verbose knowledge sources like PDFs, reports, or academic papers. Learn more about Map Reduce RAG in the research paper
Level 5: Agentic AI & MCP
Agentic AI refers to AI systems designed not just to respond to individual prompts, but to operate as autonomous agents capable of reasoning, planning, and executing tasks using tools, memory, and feedback loops. Unlike simple LLMs that answer static questions, Agentic AI can break down a high-level goal into sub-tasks, make decisions, call APIs, retrieve documents, and adapt its behavior based on intermediate outcomes. Frameworks like LangGraph, AutoGPT, and CrewAI enable these capabilities by allowing LLMs to interact with multiple components in a workflow.
For example, an Agentic AI assistant could receive a task like “create a market research report,” then autonomously search online, summarize findings, generate graphs, and format the report all without direct step-by-step instructions from a user.
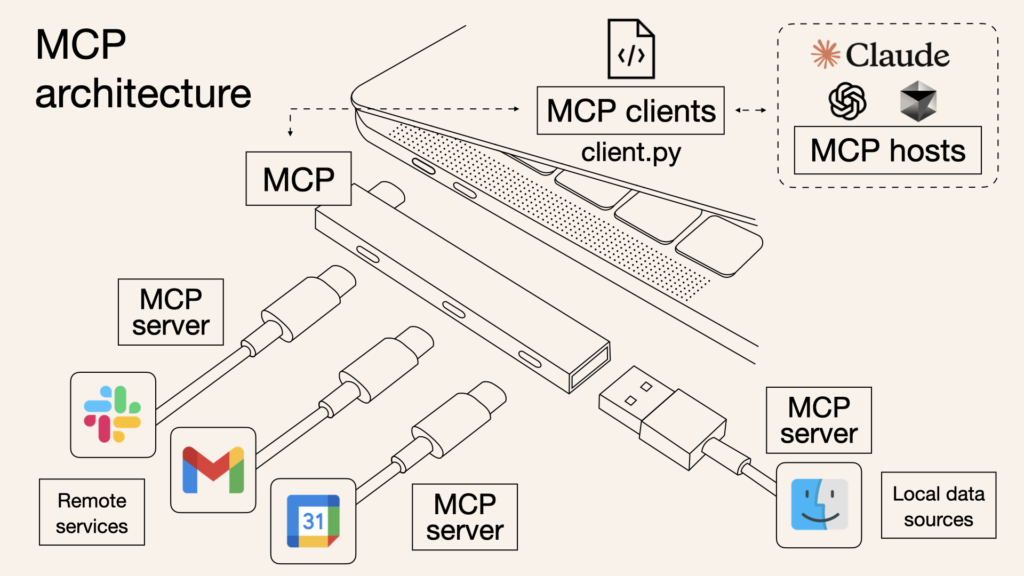
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools. - Anthropic
Model Context Protocol (MCP) server acts as a smart middleware that lets developers build AI agents capable of using real-world tools like Slack, Gmail, Google Calendar, Notion, and internal APIs without hardcoding long prompts. Instead of manually stuffing raw app data into prompts, you define a set of tools and structured inputs the AI should be aware of. The MCP server then packages that context cleanly and feeds it into Claude (Anthropic’s LLM) so it can reason intelligently across everything. For instance, imagine building an AI executive assistant: you can register tools like calendar.getEvents, gmail.listImportantEmails, and slack.fetchProjectUpdates, and provide structured context like your meeting schedule, priority inbox, and Slack discussions.
Then, when the user asks “What should I focus on this morning?”, Claude receives that question along with all relevant context from the MCP server and generates a task-aware response like, “You have a 10 AM client meeting and two important emails from finance, do you want me to summarize them or draft replies?” No prompt engineering required the MCP server handles the orchestration. Similarly, in customer support workflows, MCP can unify Zendesk tickets, product FAQs, and previous email threads so that Claude can act as a smart triage assistant. This design allows developers to wire up tools, pass data, and let the LLM operate as a full-stack agent that’s aware of the user, the task, and the surrounding context.
Level 6: Fine-tuning LLMs
Fine-tuning is the process of taking a pretrained language model (like LLaMA, Mistral, or Claude) and teaching it to perform better on a specific task or domain by training it further on curated, labeled data. Think of it like customizing a general-purpose brain to become an expert in your area such as legal contract review, customer support, or code generation in a niche programming language.
If pretraining is like teaching someone every language in the world, fine-tuning is like enrolling them in law school or giving them on-the-job training at your company.
1.Full Fine-Tuning:
Full fine-tuning involves updating all of a model’s internal weights using your custom dataset. It essentially retrains the entire model from its current state, allowing for deep changes in behavior, language, and tone.
Use Case: Best suited for highly specialized applicationssuch as fine-tuning a large model on legal documents or scientific researchwhen you need maximum control and have access to significant compute resources.
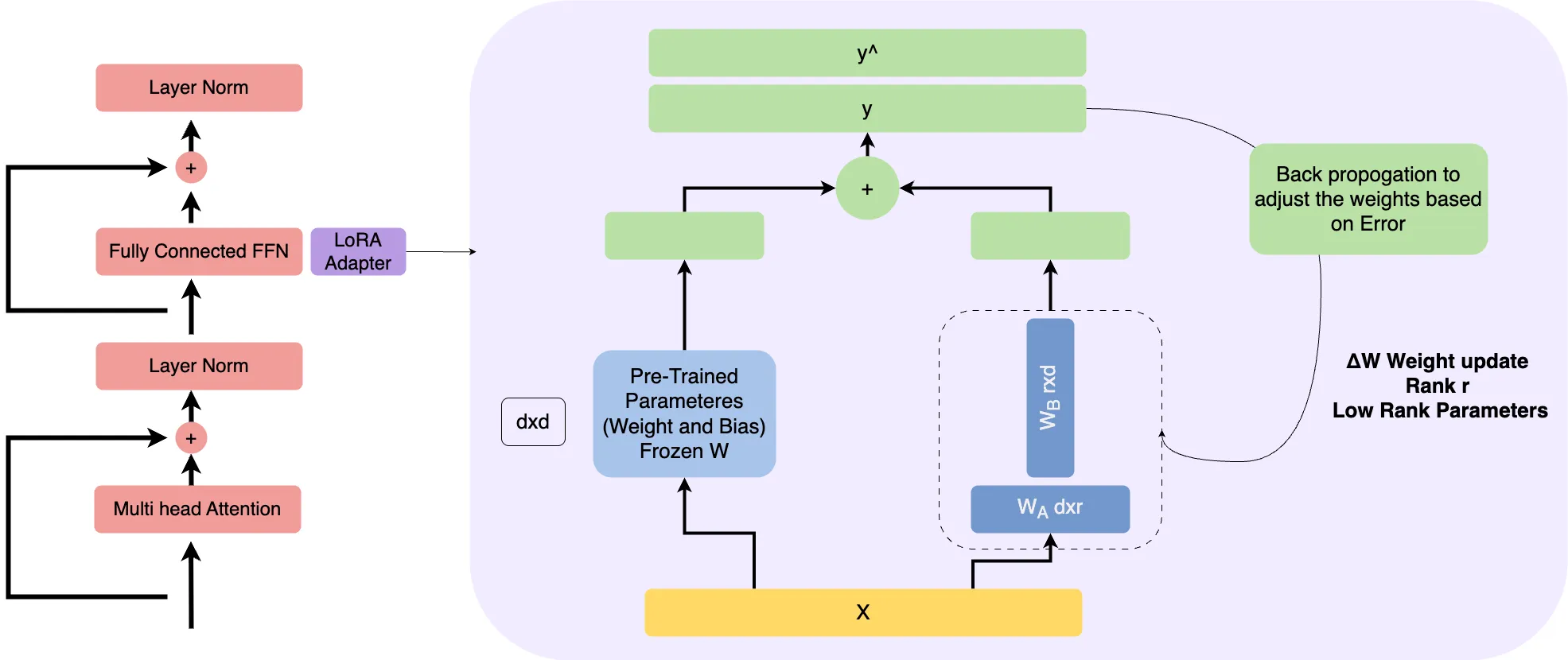
2. LoRA (Low-Rank Adaptation):
LoRA is a parameter-efficient fine-tuning method that keeps the original model weights frozen and injects small, trainable adapter modules into the network. This dramatically reduces the number of parameters being updated while still enabling the model to learn new patterns.
Use Case: Ideal for adapting large language models to new domains or use cases (e.g., financial analysis, customer service tone) without needing massive compute power.
3. QLoRA:
QLoRA builds on LoRA by adding quantization, which compresses the model to use lower-precision formats like 4-bit or 8-bit, enabling it to run on consumer hardware such as a single 24GB GPU. This makes it possible to fine-tune massive models efficiently on a laptop or small server.
Use Case: Perfect for developers and small teams who want to fine-tune 7B+ parameter models locally or on budget-friendly infrastructure.
4. Instruction Fine-Tuning (SFT):
Instruction fine-tuning teaches the model to follow commands or perform tasks by training it on a dataset of prompt-response pairs. Instead of raw text or general data, this approach explicitly shows the model how to respond to natural language instructions in specific formats.
Use Case: Commonly used to train general-purpose assistants, like those found in ChatGPT or Claude, where the model must follow user instructions across diverse domains.
When to use Fine-Tuning
| Need | Use Fine-Tuning? | Alternative |
|---|
| Custom tone or workflow | Yes | Prompt + LoRA |
| Up-to-date content | No | RAG |
| Internal document QA | No | RAG + Re-ranking |
| Small structured dataset | Yes (LoRA/QLoRA) | Instruction tuning |
| Multi-turn task agent | Maybe | Agent framework + RAG |
Techniques:
- LoRA / QLoRA (low-cost fine-tuning)
- SFT (Supervised Fine-tuning)
- DPO (Direct Preference Optimization)
Tools: Hugging Face, PEFT, TRL
Level 7: Pretraining from Scratch
Pre-training in the context of large language models (LLMs) refers to the initial phase where the model is trained from scratch on a massive corpus of text data, often sourced from the internet, books, code repositories, academic papers, and more. This stage is where the model learns the foundational structure of language: grammar, reasoning patterns, world knowledge, factual information, and general context. During pre-training, the model doesn’t learn how to solve specific tasks but instead becomes a general-purpose language understanding and generation engine by predicting the next word (or token) in a sequence across billions of examples.
Pre-training is computationally expensive and resource-intensiveit often requires thousands of GPUs running in parallel for weeks or months. This is why pre-training is typically performed by large organizations, AI research labs, or companies building foundational models like OpenAI, Meta, Google DeepMind, Anthropic, or Mistral. The output of this process is a base model like GPT-3, LLaMA, or DeepSeek that understands language at scale but hasn’t been customized to do anything specific.
| Model Name | Size (Parameters) | Estimated Cost (USD) | Notes |
|---|
| GPT-3 (OpenAI) | 175B | ~$4.6 million | Trained on V100s in 2020 |
| GPT-4 (OpenAI) | 1+ Trillion (Mixture of Experts, MoE) | ~$50–100 million+ | Architecture still undisclosed |
| LLaMA 2 (Meta) | 65B | ~$2–3 million | Optimized on A100s, open weights |
| LLaMA 3 (Meta) | 70B+ | ~$5–8 million | Uses advanced data curation, tokenization |
| PaLM (Google) | 540B | $9–12 million | Estimated via TPUv4 costs |
| Chinchilla (DeepMind) | 70B | ~$2 million | Trained on more data with smaller size |
| Mistral 7B | 7B | ~$500,000 – 1 million | Highly efficient architecture |
| Bloom (BigScience) | 176B | ~€4 million | Fully open, trained collaboratively |
In short, pre-training is like building the engine of a car it’s incredibly complex, expensive, and usually unnecessary if someone has already built a world-class engine. Most of us just need to customize how the car drives. So unless you’re trying to build the next foundational model or operate under extreme regulatory, linguistic, or research constraints, leveraging pre-trained models will save you massive time, effort, and infrastructure costswhile still delivering excellent results.
Conclusion
Navigating generative AI becomes easier when you break it down into levels. Whether you’re writing simple prompts (Level 0), deploying local models (Level 2), or building retrieval systems (Levels 3–4), each step unlocks more capability. As you move upinto agentic workflows (Level 5) and fine-tuning (Level 6)you gain greater control and customization. While full pretraining (Level 7) is reserved for large research teams, understanding its scope helps frame what’s possible.
You don’t need to be an ML expert to build with AI just start at the level that fits your goals and grow from there. GenAI isn’t one giant leap; it’s a staircaseand now you know how to climb it.
Start at the level that suits your current goals and climb as you grow.



 Amarnath Thillai
Amarnath Thillai